2020. 10. 12. 22:17ㆍTIL

최근 react 의 라우팅 방법에 대해서 의문점이 들어서 여러 가지 자료를 보고 조사를해 보았다.
여러 자료를 보면서 헷갈렸던 부분들도 있었다. 이제 부터 내가 이해한 부분을 간단히 설명해보겠다.
처음 매우 헷갈렸던 부분은 기존의 ssr 방식이였다. 지금의 ssr과 예전의 ssr 방식은 좀 뭔가 다른 부분이 있던것 같았다.
그 답은 정답인지 모르겠지만 스택오버 플로우 답변을 통해서 알 수 있었다.
해당 답변에서 이러한 설명이 있다 => "지금은 URL이 해석되는 곳이 2곳 이지만 옛날에는 1곳 뿐 이였다."
이 설명으로 애매모호하던 부분의 의문증이 풀렸다.

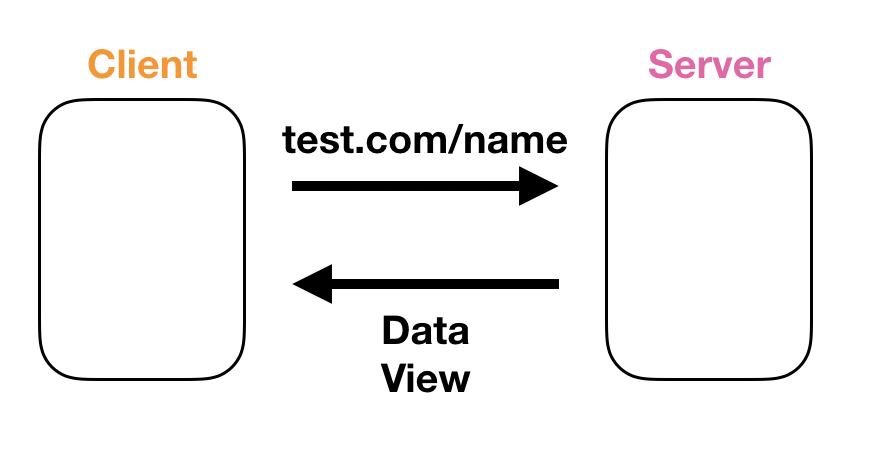
옛날은 위의 그림의 위쪽 표 같은 방식일 때를 말하고 지금은 아래쪽표와 같은 방식일 때를 말하는것 같다.
1.server에서 뷰와 데이터를 전부다 처리하는 ssr의 경우
클라이언트와 서버는 동일한 url을 가진다.
1. 클라이언트가 페이지에 접속하면
2. 접속한 페이지의 url을 읽고 해당 페이지의 요청데이터와 뷰를 보내준다.
간단하게 위와 같이 이해를 하였다. 좀 더 자세한 이해를 원한다면 구글링을 ...
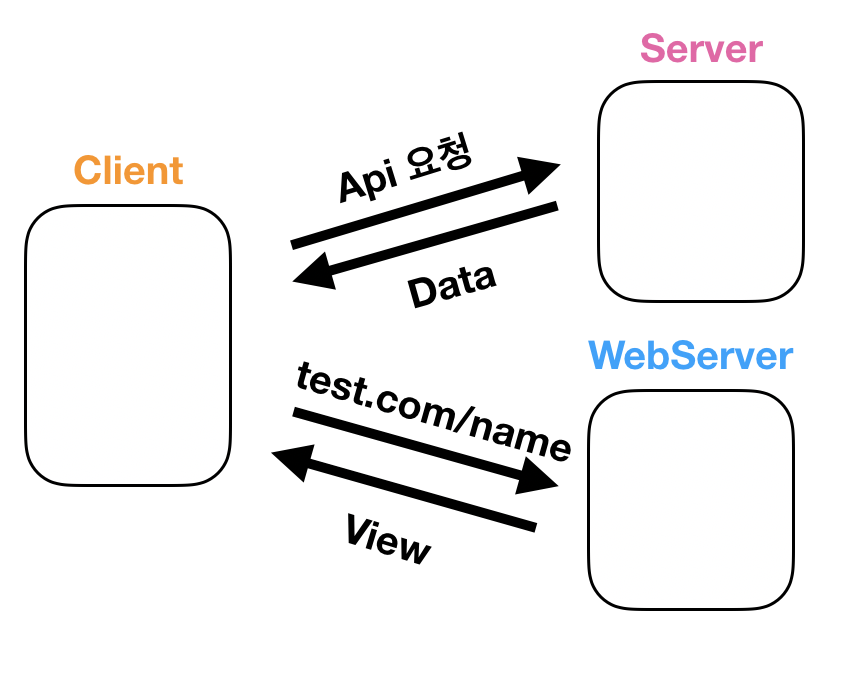
2. server 에서는 데이터 처리만 하고 front에서 server를 만드는 ssr의 경우
위의 표에서 보듯이 나는 JSP/Servlet이 하는 웹서버 역할을 프론트 엔드에서 구현을 했다고 이해를 하였다.
그래서 서버와 클라이언트의 url은 동일할 필요가 없다. 좀 더 정확히 말하자면 프론트에서 웹서버를 구현하여 url을 맞춰 주기 때문에 백엔드 서버와 url을 맞출 필요는 없다는게 더 정확한 설명이지 않을까하는 생각이 든다.
1. 클라이언트가 페이지에 접속하면
2.필요한 리소스를 웹서버를 통해 가져오고
3.필요한 데이터는 서버로 api 요청을 통해 받아온다.
d2.naver.com/helloworld/7804182
'TIL' 카테고리의 다른 글
| [TIL] React FunctionComponent props generic 으로 받기 (0) | 2020.10.20 |
|---|---|
| [TIL] 10.15 next.js getIntialprops, getServerSideprops, getStaticProps 의 차이점 (0) | 2020.10.15 |
| [TIL] 10.08 sass include media 와 exclude 순서 (0) | 2020.10.08 |
| [TIL] 09.24 box shadow naming (0) | 2020.09.24 |
| [TIL] 09.23 tab 읽지않음 표시 기능 (0) | 2020.09.24 |